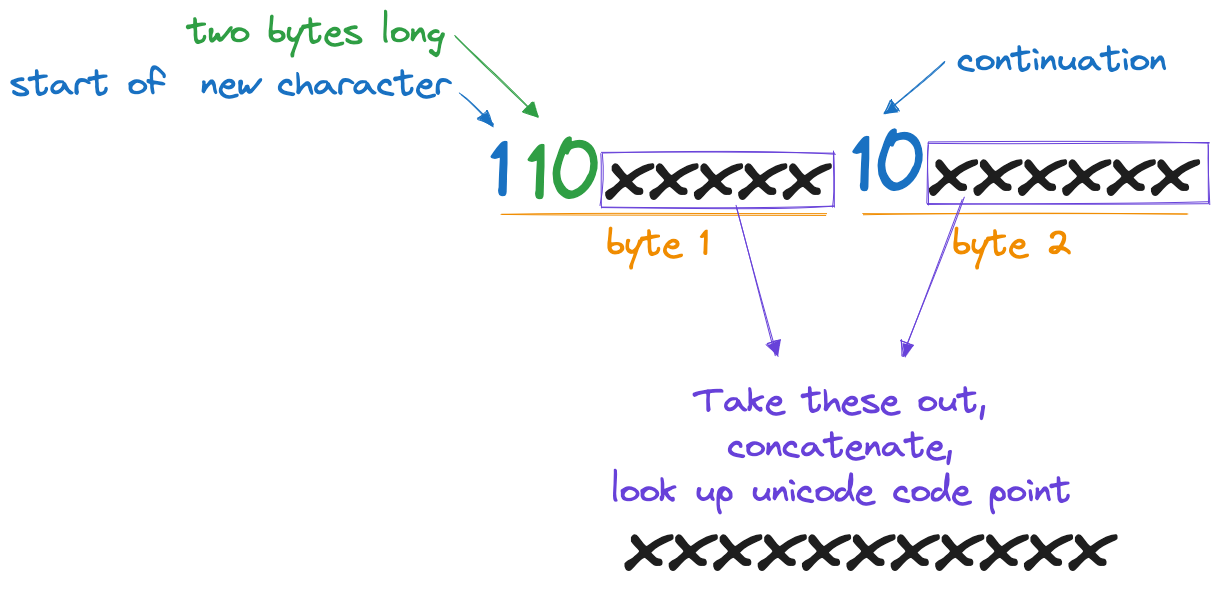
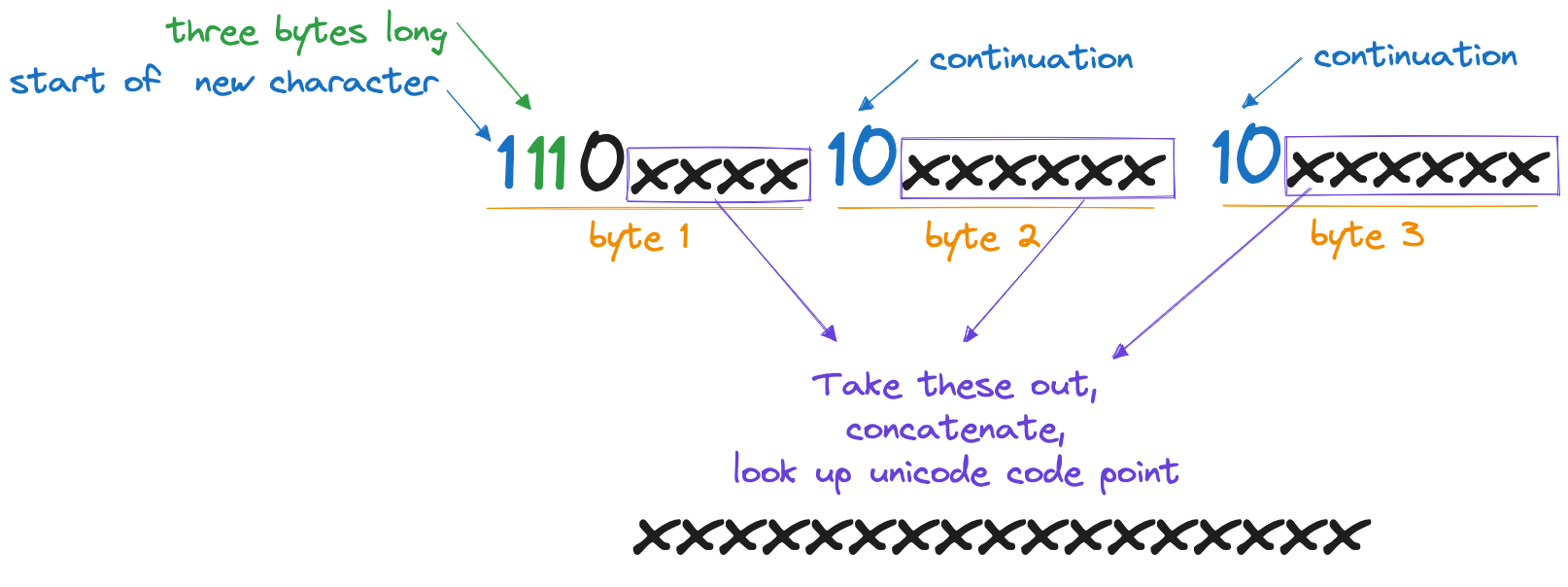
UTF-8
UTF-8 (Unicode Transformation Format - 8-bit)
- It's a variable-width character encoding for Unicode. It can represent every grapheme in the Unicode standard using one to four bytes.
- ASCII characters are represented in UTF-8 with a single byte, which maintains compatibility with ASCII.
- Grapheme from other scripts and symbols are represented with more bytes as needed.
- Thus, it's very efficient in handling English text while still supporting a wide range of international characters.
Encoding
Some of the challenges UTF-8 wanted to solve:
- In English it's necessary to get hid of all the zeros an ASCII character has when represented in UTF-32.
- Old computers interpret eight zeros in a row (NULL character) as this is the end of a string.
- Be backwards compatible.
- For ASCII it just adds a leading 0.
- ASCII: 1000001 -> A
- UTF-8: 01000001 -> A
- Null character is encoding as all zero: 0000000.
- There is a modified UTF-8 to deal with this.
For others: